
Beyond Top-K: Pipeline Parallelism Over Slow Networks
A progress update on the core problem in Protocol Learning.

Protocol Learning is multi-participant collaborative training and inference of foundation models over the internet. Core to the realisation of Protocol Learning is the ability to carry out a multi-party training run over the internet, when the model itself is split across an elastic and dynamic pool of compute.
Today's AI infrastructure isn't designed for that. The entire stack is premised on the assumption that devices are co-located. In the decentralised case, this is not true. Hence, the ways in which models are parallelized over devices become bottlenecked by communication overhead, when devices are geographically separate and bandwidth is low, and training slows to a crawl.
At ICLR 2025, we shared early results from our ongoing research at the MCDC workshop. In Beyond Top-K: Structured Sparsification for Compression in Pipeline Parallel, we introduce a novel method that enables efficient model-parallel training over low-bandwidth, heterogeneous networks—a setting traditionally limited by communication overhead. Unlike prior approaches that focus on compressing individual gradients, our technique compresses the inter-layer communication itself while preserving essential structural information. This leads to up to 90% compression, with 2× training throughput and 12× inference speedups, even over connections as slow as 80 Mbps.
Until now, compression in pipeline-parallel training has largely relied on numerical quantization, typically reducing activation gradient size by at most 50%. Sparsification-based methods have struggled to go beyond 10% compression without hurting model performance. Our approach breaks through these limits: we achieve 90% compression without degrading performance, without lowering numerical precision, by leveraging structured sparsification that aligns with the underlying model architecture. This opens the door to efficient, scalable training across resource-constrained and volunteer-driven compute environments.
While promising, 2x training speedup is not sufficient to allow decentralized training to perform on par with centralized, as the bandwidth is 100-1000x more constrained (and we only compress 90%). In some sense, this work serves to underline the severity and difficulty of the problem. Significant work remains, and Pluralis isn’t going to stop until it’s solved.
Why Model Parallelism Matters in Decentralized AI
A lot of prior work has focused on data parallelism (DP), and for good reason. It’s simple to scale, relatively well supported by infrastructure, and compatible with many gradient compression techniques.
But there’s a critical drawback in applying DP to decentralized AI: every participating node must host a full copy of the model.
That’s fine for enterprise clusters. But in a truly community-driven setting, where compute is contributed voluntarily—by researchers, hobbyists, or small labs—the assumption that every node can store and run tens to hundred of billions scale parameter models is unrealistic. Even with aggressive weight quantization, the memory and compute requirements for hosting a full LLM replica create a non-trivial lower bound on node capability. For instance, the biggest model that can be trained on a standard 4090 RTX GPU is around 400M parameters.
Simply put: data parallelism excludes low-resource nodes, and hence the majority of individuals, from participation, and cannot scale into the 100b+ parameter setting.
This is where model parallelism, especially pipeline parallelism (PP), becomes essential. PP allows us to shard the model across multiple devices, assigning only a few layers to each node. This drastically lowers the memory and compute requirements per node, making it feasible for small devices to collaboratively train large models.
But model parallelism introduces its own bottleneck: activations and gradients must be passed between nodes, often at every layer. And when nodes are connected by low-bandwidth networks (as they are in decentralized settings), this communication cost can become dominant, as these activations are often on the order of hundreds of megabytes.
The Challenge: Compression for PP Isn’t Just Harder—It’s Different
Traditional gradient compression techniques like Top-K and quantization work well in DP, where gradients are shared across model replicas and compression errors are easy to smooth out due to gradient redundancy.
In PP, the story is different. Activations and activation gradients are passed between layers, and every layer introduces its own compression error. These errors don’t stay local—they propagate forward and backward. In fact, as we show both theoretically and empirically, the error grows exponentially with depth.

Figure 1: Standard Compression techniques (top-k) applied to the Pipeline-Parallel setting, where layers are split over devices. Compression errors accumulate and destroy model quality, often preventing convergence entirely.
Since the communication involves intermediate activations and activation gradients, which are not as redundant as parameter gradients, we need a more structure-aware approach to compression.
Our Solution: Preserve the Column Space
Instead of compressing individual elements, we compress the column space of activation and gradient matrices.
Why column space?
Because in Transformers, all computations—queries, keys, values, feedforward projections—operate within the column space of the activations. Misalign the column space, and you misalign the model. That’s why preserving this space is critical for both forward accuracy and backward gradient flow.
We formalize this using principal angles between subspaces, and derive theoretical bounds showing how Top-K aggressively disrupts the column space—especially at high compression rates—while our column-based masking maintains structural integrity even at 90% compression.
For a detailed description of the method; read our paper here.
Real-World Results: Decentralized Training on 80 Mbps Networks
We ran experiments on LLaMA-3 style decoder-only models trained on the C4 dataset. Using GPipe across 8 A10g GPUs (24GB VRAM), we simulated slow interconnects (as low as 80 Mbps), a realistic approximation of wide-area volunteer compute networks.

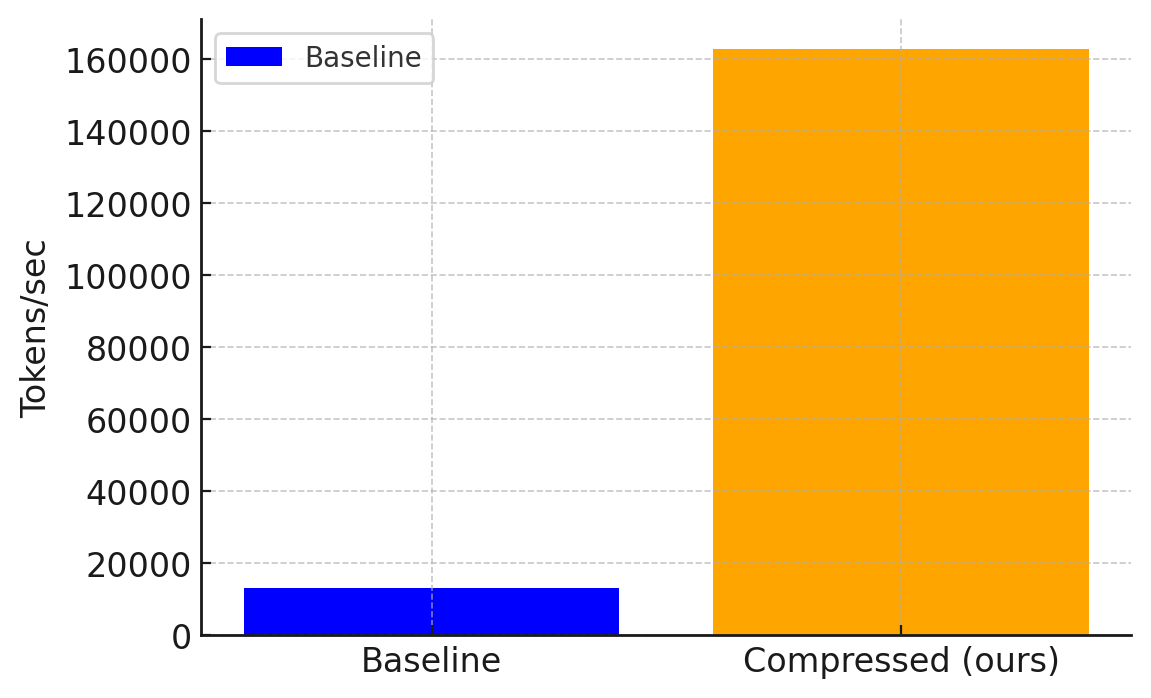

Figure 2: Throughput at training (inference) and during training (bottom) in tokens per second for a standard 800M parameter Lamma like model over 80mbps network.
Our method achieved:
90% compression with stable convergence
2× training throughput and 12× inference throughput compared to the baseline
Graceful performance even under stochastic low-bandwidth conditions
Row masking (which does not preserve column space) failed completely—reinforcing our core intuition.
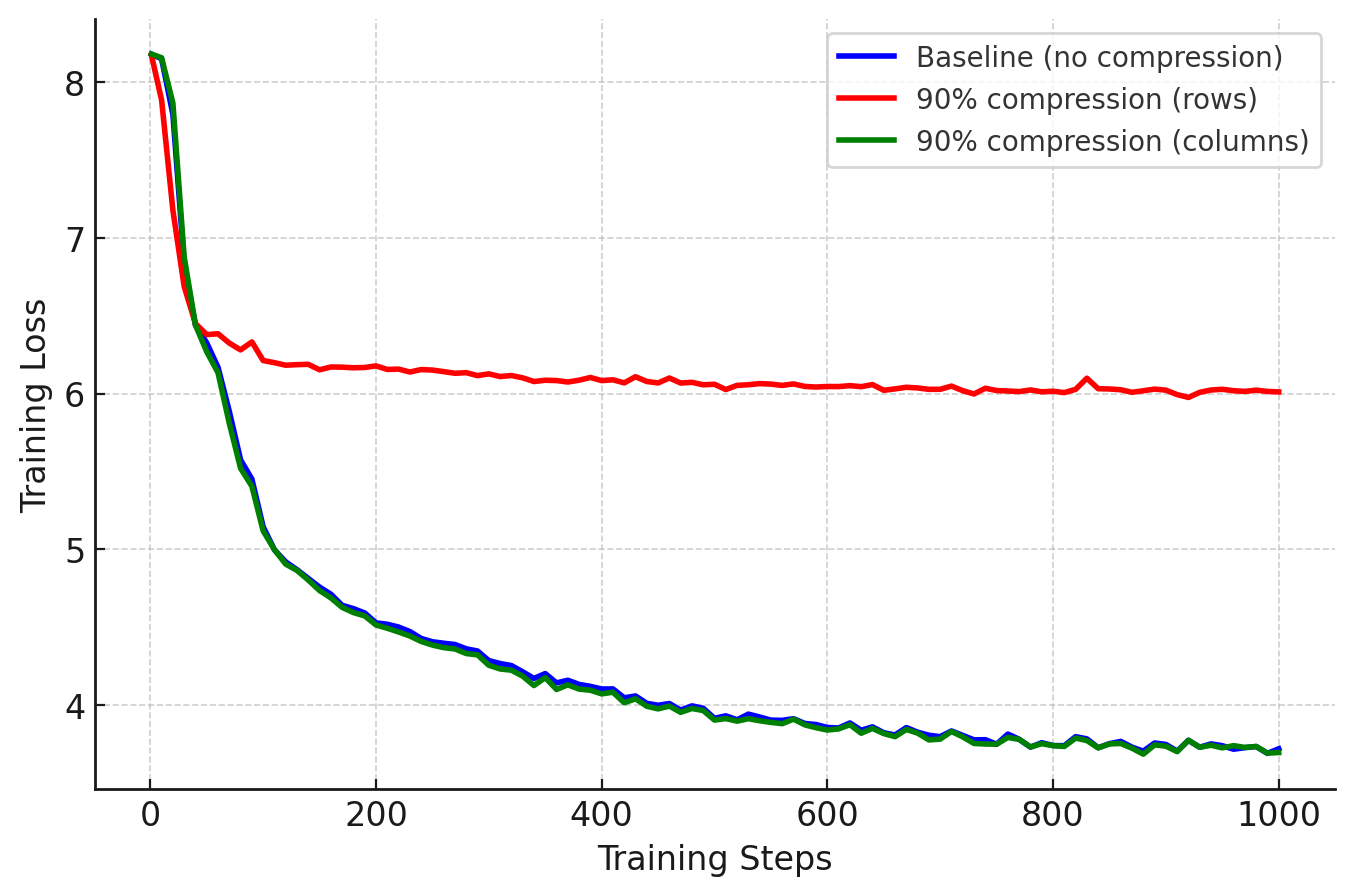
Figure 3: Compressing in the column space is critical to effective PP communication efficient training. Row-wise compression significantly reduces model performance.
What This Unlocks for Decentralized AI
This work is a preview to other results we will release shortly. While promising, 2x training speedup is not sufficient to allow decentralized training on par with centralized, as the bandwidth is 100-1000x worse, and hence, significant work remains.
However; it emphasizes the scope and scale of the problem that must be solved. By making model-parallel training communication-efficient, we can finally start building decentralized training systems that:
Allow low-resource nodes to meaningfully contribute
Scale LLMs over volunteer and edge infrastructure
Support bandwidth-constrained settings, from academic labs to globally distributed compute collectives
Shrinking the communication cost is the core research problem required to lower the barrier to entry for decentralized AI.
Final Thoughts
The future isn’t centralized, it’s in protocols. We must get low bandwidth, multi-participant, model parallel training to work for this to be feasible. Our work shows the first inklings of progress on a problem which will fundamentally alter the economics of the foundation model layer.
This was a great read, thank you so much for all the work the Pluralis research team & yourself are putting in to push the technical challenges of scaling decentralized AI forward. Decentralized compute, training and inference at scale would also allow communities to scale their own bespoke hardware that also doubles as their gateway to contributing to tokenized networks embedded with AI models of multiple shapes and forms. This sparks so much in all our brains, thank you once again