
Efficient Asynchronous Low-Bandwidth Training on Heterogenous GPUs
A new asynchronous method that surpasses synchronous methods in low-communication training while supporting heterogenous GPUs.

Pluralis Research is working on Protocol Learning — multi-participant collaborative training and inference of foundation models over the internet. Protocol Learning aims to move beyond closed proprietary compute clusters, and towards a future where anyone, anywhere, can contribute, and benefit from truly open frontier models. However, training base models in this way is largely considered infeasible. In this blog post we summarise early work from Pluralis on solving this problem (for technical readers, the paper can be found here).
A core problem in Protocol Learning is the ability to support training on heterogeneous GPUs with drastically varying compute capabilities, connected over the internet. This is in stark contrast to the current AI training infrastructure which requires co-located, homogenous GPUs, connected via high-bandwidth interconnects within a datacenter. Naively distributing model training over heterogeneous GPUs would slow the whole training procedure due to the straggler effect – the slowest GPU bottlenecks training. This means, even with one slow GPU, training would become prohibitively slow and result in decentralised training being uncompetitive.
Efficiently making use of many devices of variable computational power and memory capacity is a core requirement of Protocol Learning.
At ICLR’25 we preview some early research findings where we show asynchronous optimization methods enable support for heterogeneous GPUs for language model training overcoming the straggler effect. Specifically, our MCDC workshop paper titled Momentum Look-Ahead for Asynchronous Distributed Low-Communication Training shows that in addition to supporting heterogenous devices, our asynchronous method consistently outperforms the synchronous alternative.
A Primer on Low-Bandwidth Data Parallel
In a traditional Data Parallel (DP) setup, each GPU computes the gradients on its own data-split, and communicates it to the parameter server. The server then updates the parameters by aggregating the gradients from all GPUs and distributes the updated parameters back to the GPUs for the next iteration. This process is communication intensive as the gradients are communicated at each iteration.
Inspired by the federated learning literature, DiLoCo shows that infrequent communication with the server is sufficient for convergence, effectively reducing the communication overhead. Specifically, DiLoCo formulates DP as a bilevel optimization problem, where the inner-optimization is performed on each GPU (e.g., using AdamW) and the server model is updated by synchronizing the model parameters from all GPUs (i.e., outer-optimization), at a predefined interval (e.g., every 50 inner-iterations). DiLoCo synchronizes the models by averaging the outer-gradients from all GPUs and taking a small step in the average direction using the Nesterov method.
Why Asynchronous?
The reason for the straggler effect is the synchronization step, which waits for all GPUs to complete the inner-optimization. Therefore, the training speed is bottlenecked by the slowest GPU and all other GPUs stay idle until the slowest GPU completes the inner-optimization. See illustration in Fig. 1 below.

Removing this synchronization step overcomes the straggler effect, eliminating the idle time and improving compute utilization. However, this comes at the cost of an optimization challenge known as gradient staleness.
Optimization Challenge: Gradient Staleness
Since the server updates its parameters whenever it receives the outer-gradient from a GPU (without waiting for other GPUs to complete), the server parameters would have been updated multiple times while a particular GPU is performing its inner-optimization. This is illustrated in Fig. 2.
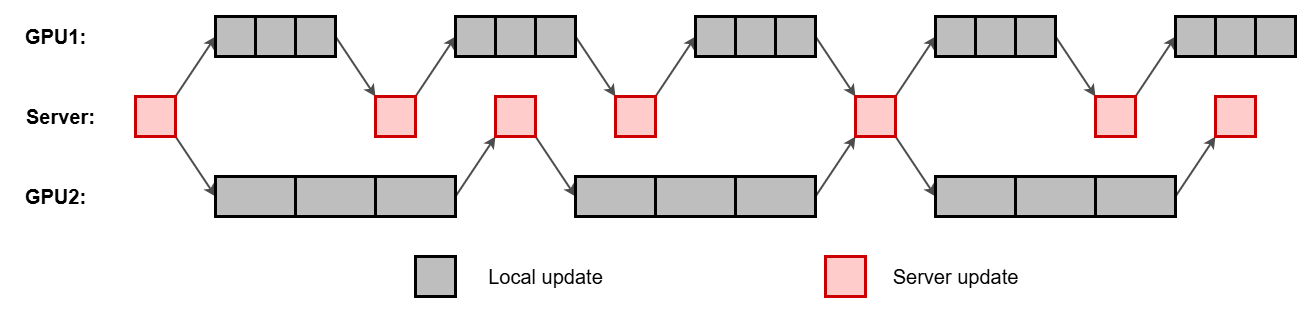
Therefore, the outer-gradients communicated by a GPU are older than the server parameters at a given iteration – the outer-gradients are stale. This staleness is detrimental for convergence and needs to be compensated using delay correction mechanisms.
Our Solution: Momentum Look-Ahead
Our idea is to correct the staleness directly in the parameter space using a look-ahead. Specifically, we extrapolate the negative direction of momentum so that the outer-gradients can be computed at a point closer to the ideal one, alleviating staleness. This method does not make any assumptions about the loss function or gradients, and the only assumption is that the outer-update directions can be approximated using momentum.
To ensure momentum robustly approximates the outer-update steps, we compute it as an Exponential Moving Average (EMA) of the outer-gradients. Since EMA estimates the average, it provides a smooth approximation to potentially noisy outer-gradient steps, ensuring that the look-ahead step is robust. Our method can be thought of as a variant of the Nesterov method where the momentum computation and the look-ahead direction are modified to handle gradient staleness.
Results
We perform experiments on the WikiText dataset using the NanoGPT architecture with approximately 90M parameters. We compare our method with the synchronous DiLoCo method, and two asynchronous methods: 1) vanilla Nesterov method (Async-DiLoCo); 2) the buffer based delayed Nesterov method (Async-DiLoCo-DN). In all our experiments, our method outperforms all methods yielding faster convergence.

To cater for heterogeneous GPUs, one trick is to adjust the number of inner-steps to be inversely proportional to the compute capability of the GPU, balancing the time taken per inner-optimization in each GPU. This approach is called DyLU, which improves all asynchronous methods including ours.

Implications
Asynchronous methods are appealing in a heterogeneous environment as they eliminate the idle time of GPUs, improving compute utilization and training speed. This work shows that asynchronous methods are beneficial even in the highly communication constrained (i.e. training over the internet) setup. Furthermore, asynchronous methods perform more frequent updates on the server model (up to #GPUs times more updates) compared to the synchronous method, and can therefore outperform synchronous approaches as observed in our experiments.
Altogether, we demonstrated that we can not only support heterogeneous GPUs but also improve over the synchronous methods, enabling efficient collaborative training.
Final Thoughts
These are preliminary research findings, and while promising, the setup and method are limited. Specifically, the results are on a full-model DP setting, where each GPU needs to hold and update the full model, which severely limits the model size. Furthermore, asynchronous methods alone cannot fully overcome the bandwidth limitation and compressing the amount of data communicated between GPUs is essential to achieve on par performance with a centralized setup.
Significant work remains, the problem is difficult, and we are a small research lab with limited resources, but the impact is enormous, and that makes it worth trying.