
SWARM Parallel with Asynchronous Updates
We significantly improve training reliability, robustness and speed of asynchronous pipeline-parallel training.


Protocol Learning is multi-participant collaborative training and inference of foundation models over the internet. Core to the realisation of Protocol Learning is the ability to carry out a multi-party training run over the internet, when the model itself is split across an elastic and dynamic pool of compute. Today, we're previewing more research from our lab presented as a talk at the ICLR 2025 Modularity for Collaborative, Decentralized, and Continual Deep Learning (MCDC) workshop. This work explores how to make pipeline parallelism more practical for fully elastic swarms with heterogeneous devices.
Exploring Asynchronism in SWARM Parallelism
To do this, we’ve utilized the SWARM parallelism framework, which, aside from our recent work, is one of the only efforts focused on Model Parallel training in a low-bandwidth setting. SWARM dynamically routes the computational graph for a full forward pass over various participants and is hence robust to a noisey and elastic pool of devices. Built on the Hivemind framework, it supports fault-tolerant, pipeline-parallel training with multiple worker nodes per stage. A visualisation from the original paper appears below:

In our research, we identified a bottleneck: the synchronous nature of the periodic weight synchronization step forces all nodes to wait for each other. This becomes especially problematic in elastic swarms where nodes can join or leave dynamically, and when dealing with heterogeneous devices of varying speeds. By allowing nodes to perform local updates asynchronously and only periodically synchronizing their states, we've made the system roughly twice as fast. The main technical challenge is maintaining model convergence despite the "staleness" that naturally occurs in asynchronous settings, where gradients fall out-of-sync with the model.

NAG Adaptation in SWARM
We developed a novel approach using Nesterov Accelerated Gradient (NAG) to counteract gradient staleness in asynchronous training. Unlike standard momentum, which applies a velocity term to past gradients, NAG adjusts the update direction before computing the gradient, reducing overshooting and improving stability.
The velocity component acts as a weight correction term, compensating for gradient staleness by anticipating the future weight position. This allows NAG to mitigate stale updates by dynamically adjusting the weight trajectory based on past updates and estimated future gradients.
Results
We performed experiments on the WikiText dataset using the SWARM baseline where the model used is a Transformer language model with a Llama-3 based architecture - the first time results from SWARM have been reported with a modern LLM arch. The results exceeded our expectations:
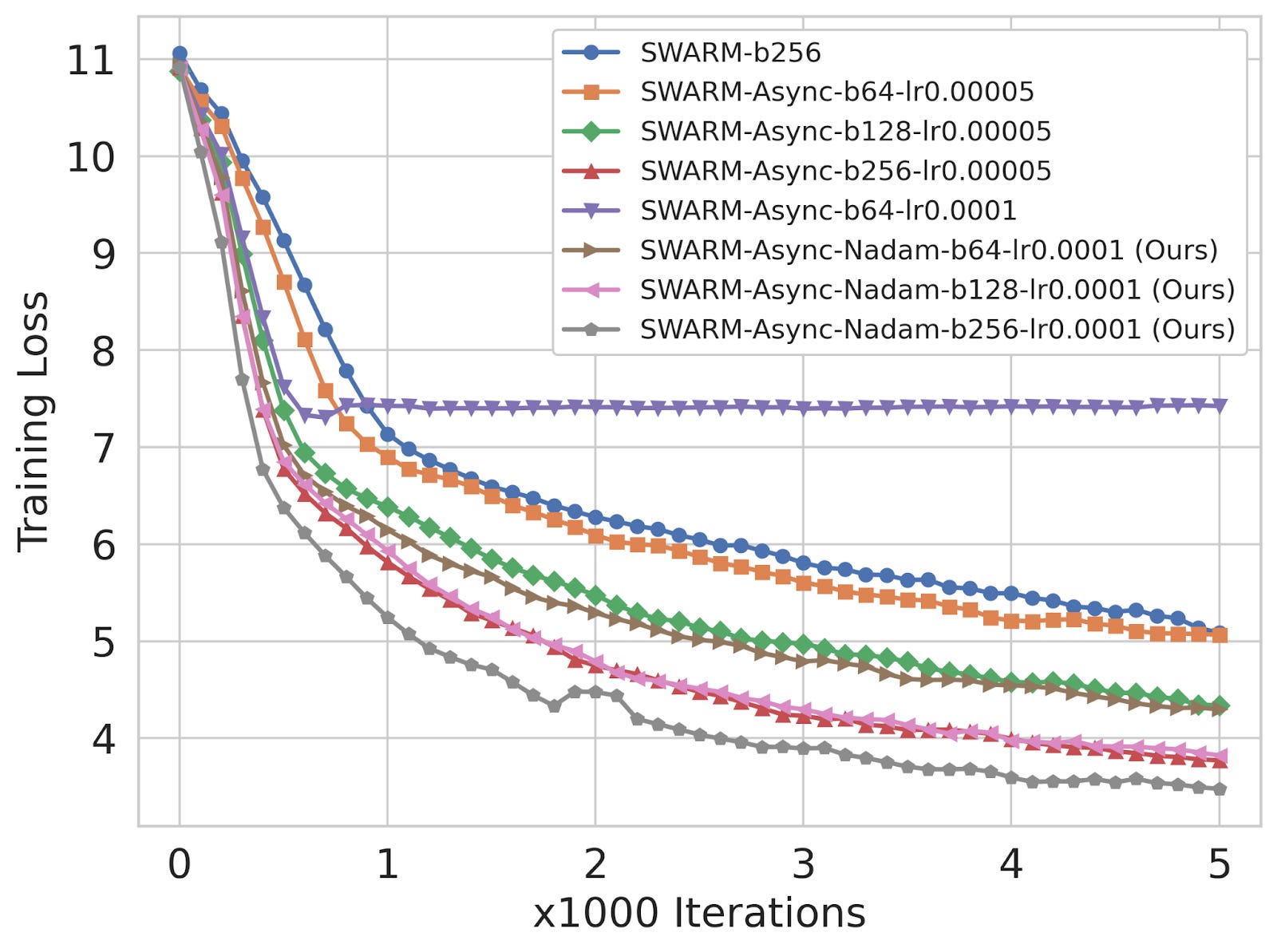
Up to 45.9% improvement in wall-clock time with a batch size of 64.
Consistent outperformance of both synchronous SWARM and basic asynchronous implementations.
Stability even with reduced warmup periods and artificial network delays.

What We Found
The main result of our work is that the NAG-adjusted asynchronicity we introduce leads to a direct improvement in model training time without sacrificing model performance. The system becomes faster, better handles elastic swarms where nodes come and go, and is more robust to heterogeneous devices with varying compute capabilities. As far as we observe, there is no drawback.

Final Thoughts
We're sharing this research as a window into our ongoing work on Protocol Learning. While there's significantly more to explore, we hope this small modification to existing approaches helps make decentralized model training a bit more practical. We'll continue investigating ways to make collaborative training more accessible and efficient, but for now, we're encouraged that even simple changes can yield meaningful improvements in this domain.